一、设置网络
1.控制面板--右上打开高级模式--网络
2.弹出界面最上面选择网络界面选项卡,选择你的网卡,默认一般都是局域网1,点击编辑
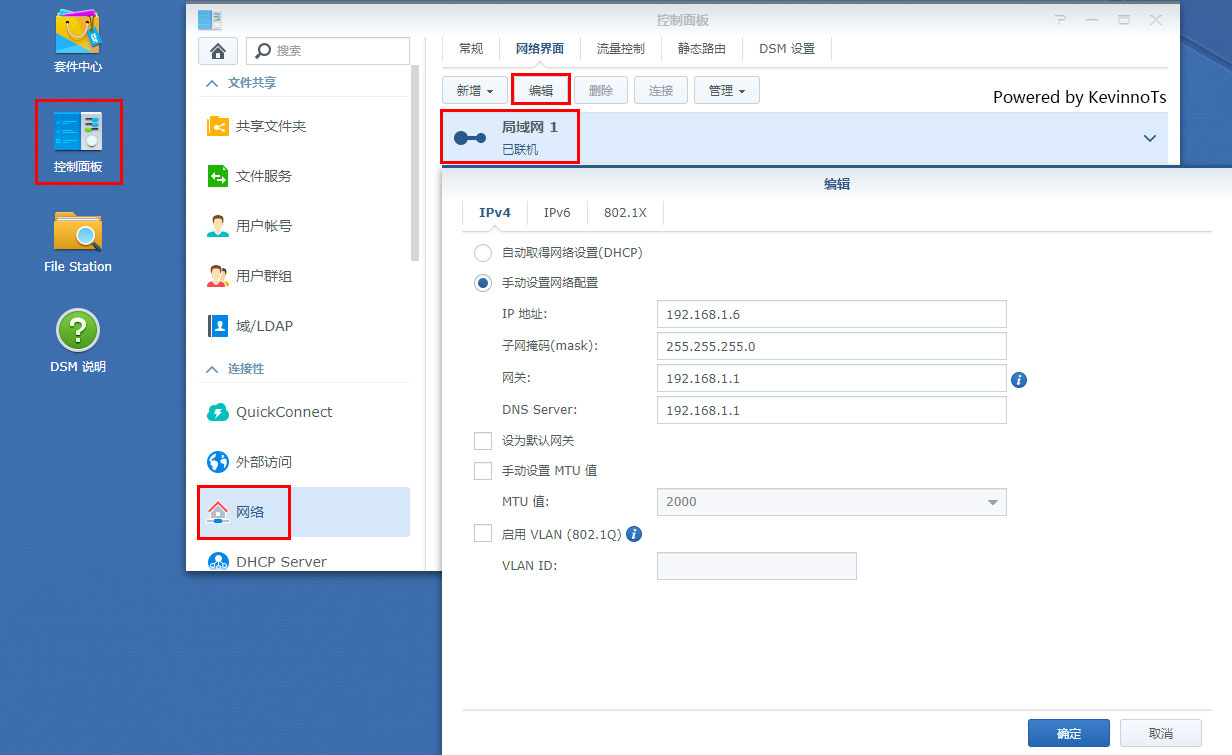
3.弹出界面在IPv4选项卡勾选手动设置网络配置,手动输入IP,子网掩码,网关,DNS
比如我的设置如下:
IP地址:192.168.1.6
子网掩码:255.255.255.0
网关:192.168.1.1
DNS:192.168.1.1
4.其他默认,点击确定保存,稍等一会儿会从新连接到网页控制界面
二、开启SSH
1.控制面板--终端机和SNMP
2.启动SSH功能打钩,端口任意未被占用的端口都行,自己记住,默认是22
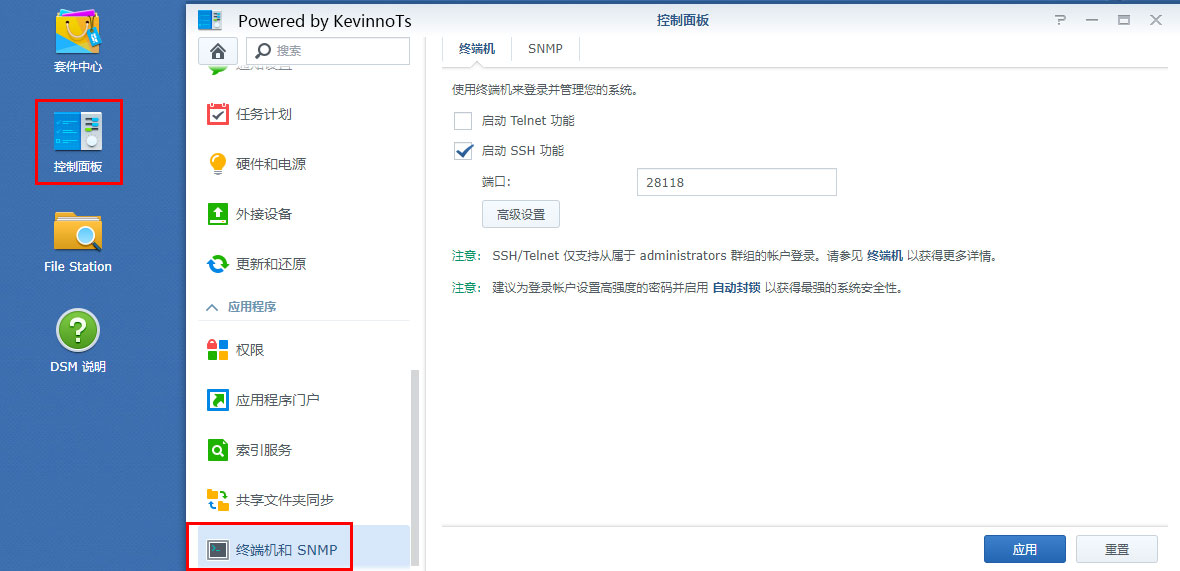
3.使用ssh工具连接ssh(推荐使用FinalShell),主机就是DSM的IP,登录输入登录网页的用户名密码即可
4.切换到root下,使用如下命令:
sudo -i然后输入该账号的密码
三、启用SHR
默认3617是不开启SHR的,如果你是918或者使用了之前已经组建过SHR阵列的磁盘的话,那么恭喜你,整个第三步可以跳过不用看了
1.什么是SHR:
SHR,即 Synology Hybrid RAID(群晖混合磁盘阵列),是一种群晖推出的自动磁盘阵列管理系统,设计初衷为简化管理的同时增加磁盘空间利用率。
如果没有冗余需求的小伙伴可以选择Basic进行管理,单块硬盘,坏了就坏了那种
对数据异常重视的小伙伴,不要把所有鸡蛋都放在同一个篮子里就好了
觉得硬盘贵,因为数据没那么值钱
2.SHR的优点:
- 适用于小白,完全不需要搞懂RAID0,RAID1,RAID5,RAID6,RAID10等等复杂的RAID系统,只需要点点鼠标,就可以创建一个最多 2 块硬盘发生故障而数据卷仍可使用的磁盘阵列(默认SHR是1块硬盘冗余的,SHR2可以支持2块硬盘冗余,但是最少要4块硬盘才可以组)
- 方便后续添加,SHR只要后加入的硬盘容量大于等于目前阵列中最大的硬盘容量即可,原有数据无任何影响
- 如果硬盘更换,同样和添加一样,只要更换的硬盘容量大于等于原来的硬盘即可,点点鼠标,不需要任何繁琐的操作
3.开启SHR:
输入如下命令,编辑配置文件:
vim /etc.defaults/synoinfo.conf进入文件后,输入/supportraidgroup,然后按回车,会搜索到该内容
...
supportraidgroup="yes"
...鼠标移动到行首,按i进入编辑模式,在其前面增加#注释掉该内容
在其下面输入一行新内容
#supportraidgroup="yes"
support_syno_hybrid_raid="yes"增加后,按ESC,退出编辑模式,输入:wq退出编辑器
输入如下命令重启:
reboot4.创建SHR
重启后,就在存储空间管理员中可以创建SHR咯
如果目前仅有一块硬盘,也是可以创建SHR阵列的,只是目前没有任何冗余,相当于Basic而已,随时可以通过增加硬盘的形式形成冗余
四、洗白
这里介绍的只是洗白方法,不提供洗白码及算号方法,请自行查找,也可以万能淘宝……
哪怕使用了全白码,依旧不建议大家使用QC,咱们用盗版就不要用得那么理直气壮了,毕竟浪费群晖带宽资源
登录SSH,并切换到root模式下
sudo -i进来后原地不动(/root目录下,如果使用其他路径,请自行修改后面所有/root/boot的内容),创建一个文件夹用来存放挂载引导盘的文件
mkdir boot挂载引导盘
mount -t vfat /dev/sda1 /root/boot这里这条命令只适用于之前文章我提供的引导文件及6.23版本系统
如你使用的是5.2-6.22之间的版本的话,使用如下命令:
mount -t vfat /dev/synoboot1 /root/boot注意:6.23使用第一条命令,5.2-6.22使用第二条命令,如果非引导盘而是二合一本文不做涉及
编辑引导文件
vim /root/boot/grub/grub.cfg进入编辑器后,上下左右移动光标,找到类似信息:
set sn=A8ODN02468
set mac1=0011322CA603输入i即可让编辑器进入编辑模式(屏幕左下角有个-- INSERT --),鼠标右键可以使用粘贴
将sn和mac1等于号后面的内容替换为你的洗白码
如多个网卡,可另起一行,输入mac2
像这样:
set sn=A8ODN02468
set mac1=0011322CA603
set mac2=0011322CA604如果要全白,sn及mac都需要通过群晖验证才可以
搞定以后先按ESC退出编辑模式,然后输入:wq回车,退出编辑器,注意是英文半角的冒号和小写字母wq
如果需要修改硬盘顺序的话,先不急的重启
如果无硬盘顺序的需求的话,输入reboot重启,即可洗白完成
洗白后如果不是固定IP的话,有可能IP地址变更,自己登录路由器管理界面查看一下即可。固定IP的话没影响
五、修改硬盘顺序
918说是最高支持9盘位,但在存储空间管理员中能看到16个坑(我也不知道咋回事)
引导盘占了一个坑……这玩意儿强迫症忍不了啊……
而且据说不改硬盘顺序影响硬盘正常休眠?那更不能忍了
在修改之前,你首先要知道你的控制器是什么,PVE下可以通过如下命令查看:
lspci -n | grep 0106我的输出结果是:
00:17.0 0106: 8086:a282
02:00.0 0106: 197b:0585
04:00.0 0106: 1b21:0612 (rev 01)如果你对ID没有概念,可以使用:
lspci -nn | grep 0106查看带名字的
然后查看直通到群晖后,有哪些控制器,命令同样:
lspci -n | grep 0106
0000:00:07.0 0106: 8086:2922 (rev 02)
0000:00:10.0 0106: 8086:a282
0000:00:11.0 0106: 197b:0585根据群晖的对比PVE的,毕竟群晖里面-nn是不带控制器名字的
对比发现,群晖的第一个控制器(8086:a282)在PVE中没有出现,那么说明它应该是PVE虚拟机给群晖的控制器,这么说大家能明白吗?
因为我的情况是PVE没有虚拟任何硬盘给群晖,只给PVE直通了两个SATA控制器,所以群晖的第一个控制器中应该只有引导盘1块硬盘
群晖的第二个控制器(8086:a282),是PVE中的第一个控制器,在PVE中通过lspci -nn | grep 0106很容易确定其为主板SATA控制器
群晖第三个控制器(197b:0585),在PVE是第二个控制器,也可以确定它为自购的M2转SATA控制器
都确定了以后,需要按自己需求进行排序了,16个坑位把他们填进去,以我自己为例(下面说的是硬件,也就是PVE查看到的)
- 主板SATA控制器有6个坑位,其中如果使用M2接口会少两个,但这不是重点,我把主板的6个SATA控制器排在1-6号
- M2转SATA带5个SATA口,我把它排在7-11
- 12-16位留空
- 引导盘把它排在16以后,这样可以达到隐藏分区的目的
在群晖中的排坑是:
- 第一个控制器(引导盘),大于1个口即可,排位在16+
- 第二个控制器(主板),6个口,排在1-6
- 第三个控制器(M2转接卡),5个口,排在7-11
我尽可能的讲细致一些,相信哪怕小白只要静下心来也能捋顺这个关系了
好,下面开始施工
与洗白一样的前面工作一样,切换到root下,挂载引导盘,编辑grub.cfg
sudo -i
mkdir -p boot
mount -t vfat /dev/sda1 /root/boot
vim /root/boot/grub/grub.cfg如果做过洗白操作,创建过/root/boot目录的可以不用执行第二步了
如果刚刚做完洗白操作,还没有重启的话,就不要执行第三步了
如果是6.22之前版本(不会还有人用5.2之前的版本吧?),挂载命令为:
mount -t vfat /dev/synoboot1 /root/boot在洗白的下面找到类似如下内容(3617默认这样):
set sata_args='sata_uid=1 sata_pcislot=5 synoboot_satadom=1 DiskIdxMap=0C SataPortMap=1 SasIdxMap=0'或者(918默认这样)
set sata_args='SataPortMap=4'其中其他参数不用管,只关注下面这两个参数(如果你那里没有也不要慌,先听我讲):
DiskIdxMap=0C
SataPortMap=1其中:
DiskIdxMap 表示排序,也就是说该控制器的第一个盘从第几个坑位开始
SataPortMap 表示个数,也就是说该控制器一共有几块硬盘位
一个确定了起点,一个确定了距离,就可以计算出终点以及该控制器上各个硬盘的坑位了,小学数学
至于编辑格式:
DiskIdxMap 以2位的16进制数值表示一组,有几个控制器需要连续输入几组。比如我的最终值为:100006,三组数转化成10进制,就是16 0 6,因为计算机语言中的计数不是从1开始,而是从0开始,所以16表示的是第17号坑位,0表示第1号坑位,6表示第7个坑位
SataPortMap 以1位10进制数值表示一组,有几个控制器需要连续输入几组。比如我的最终数值为:265,表示第一个控制器有2块硬盘,第二个控制器有6块硬盘,第三个控制器有5块硬盘。
所以最终我讲上面内容改为了:
set sata_args='DiskIdxMap=100006 SataPortMap=265'除去这两个数值,其他不用管
改完这个,还需要改一个地方,将:
set default='0'改为
set default='2'这个表示启动时,选择第三项进入系统
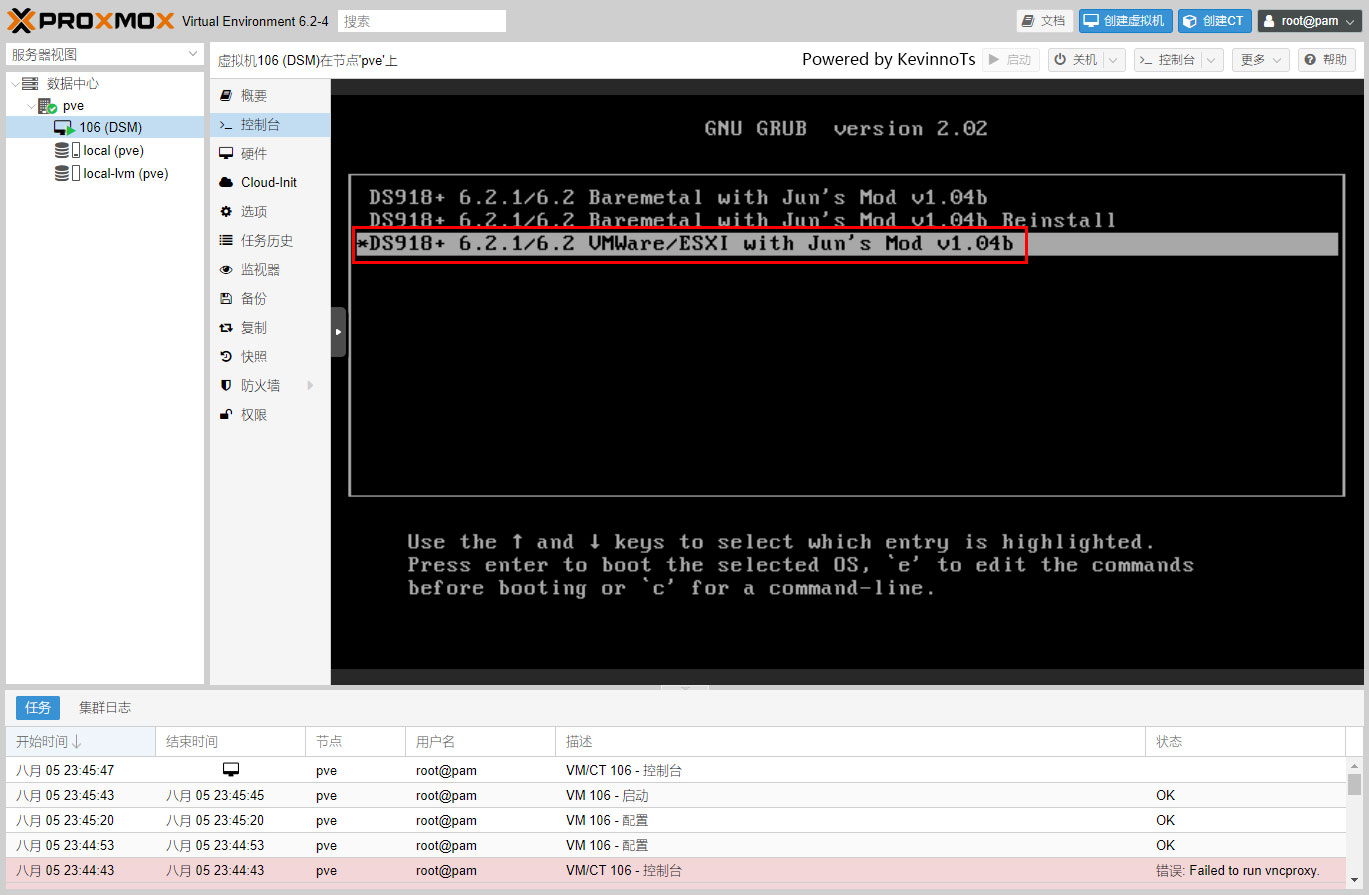
DS918+ 6.2.1/6.2 VMWare/ESXI with Jun's Mod v1.04b默认是第一项
修改的方法还记得吧?先输入i进入编辑模式,改完后按ESC退出编辑模式,然后输入:wq退出编辑器
搞定后,重启
reboot已知问题汇总:
- 没有成功通过第三项进入系统,可能会导致修改盘符失败及无法休眠
虽然修改文件指定启动时选择第三项启动,但在我这里需要至少手动选择一次才会再下次启动时自动生效,不知道为什么。如果同学们的也不会自动切换,可以尝试手动选择一次再试试看
因为设定的等待时间只有1秒,所以需要在重启时一直连按方向键上或下
什么?你不会?在PVE的中选择 >_ 控制台,即可操作
- 如确定已是第三项启动,且修改无效,可尝试更换语句
将 DiskIdxMap=100006 SataPortMap=265 放到 set extra_args_918='' 的单引号里面
像这样:
...
set extra_args_918='DiskIdxMap=100006 SataPortMap=265'
...
set sata_args=''
...- 如使用第三项启动时,出现故障,可尝试在PVE中,将
机器由默认的i440fx改为q35
六、硬盘休眠
其实休眠这个东西吧,当你装了很多软件后,很难保证不被唤醒的,尤其是下载啊,PT啊,同步啊什么的,所以如果尝试休眠,结果经常被唤醒,而唤醒的软件又是自己必须且常用的,那么还是建议你关闭休眠。因为硬盘不停的休眠再唤醒,还不如一直让他处于待机状态
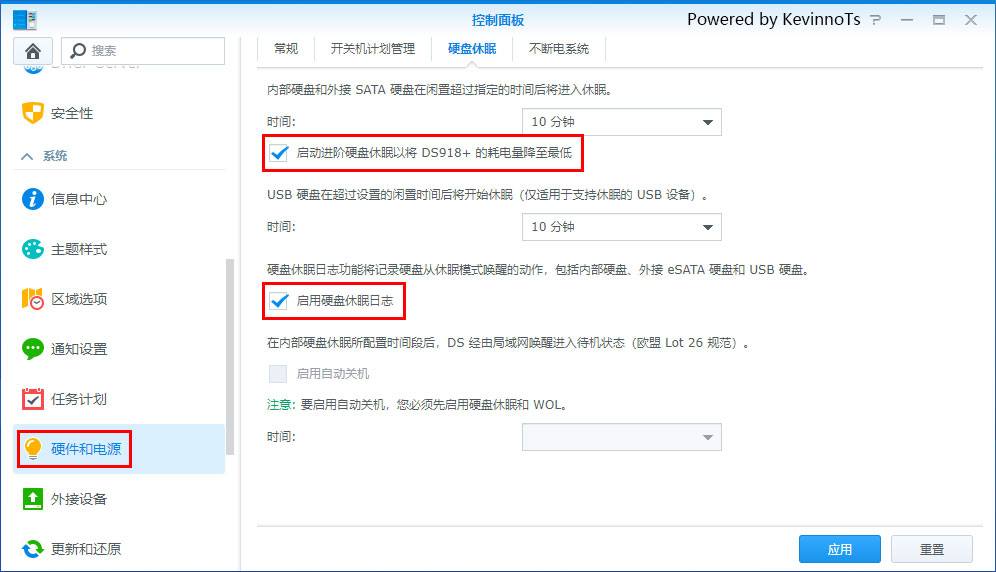
1.设置休眠
设置休眠很简单,依次进入:控制面板--硬件和电源--硬盘休眠--启用硬盘休眠并设置时间即可(同时勾选硬盘休眠日志,可以查看到硬盘被唤醒的日志记录)
2.查看休眠日志
点击左上角的主菜单,选择日志中心,左侧点击日志,其中Internal disks woke up from hibernation.的内容就是硬盘唤醒的记录
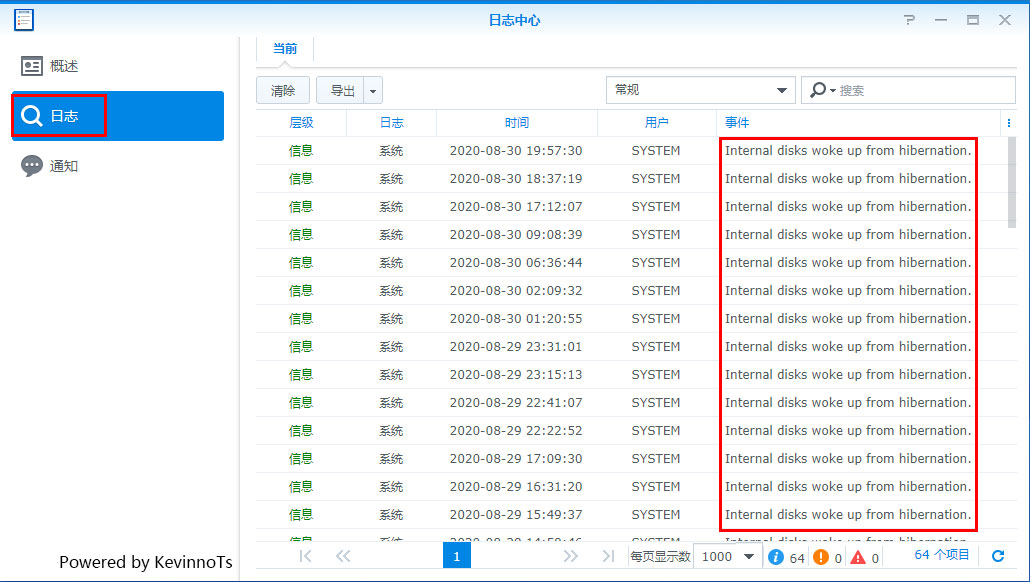
3.查看休眠调试日志
如果经常唤醒,或只要一休眠就立即唤醒,可以通过打开休眠调试日志来查看有哪些应用唤醒了硬盘休眠
依次点击左上角的主菜单--技术支持中心--技术支持服务--启动系统休眠调试模式勾选,然后在遇到问题那里选择经常唤醒
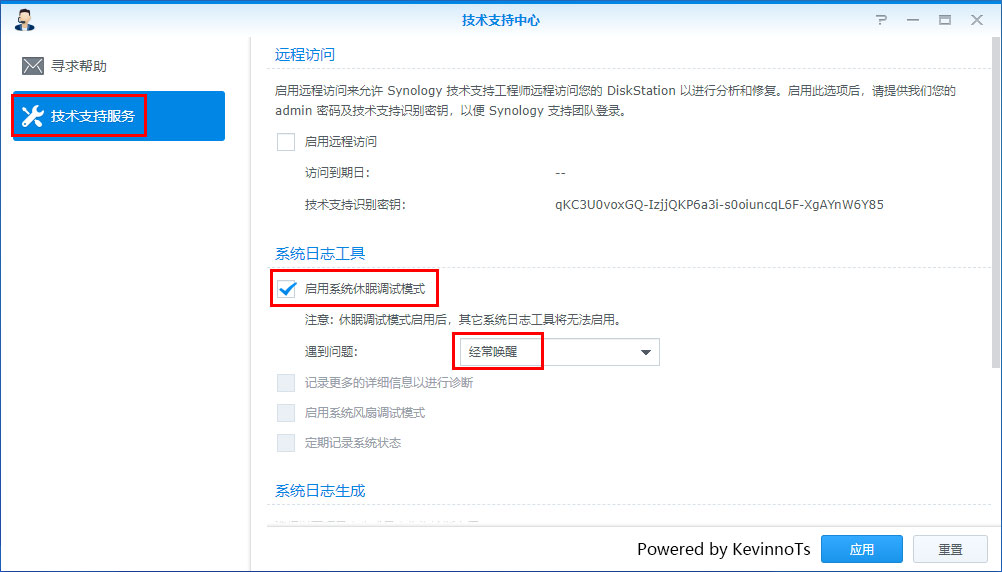
然后就可以等待硬盘休眠后查看调试日志咯
哦对了,如果想让硬盘休眠,需要关闭所有客户端及网页,比如后台控制台、SSH连接等等,如果挂载了共享文件夹也尽量先删除掉
4.分析休眠调试日志
打开日志后,会生成两个文件,分别是:/var/log/hibernation.log 和 /var/log/hibernationFull.log,后面那个是原始数据,以后面那个为准好了
可以通过如下命令查看简要信息:
tail -f /var/log/hibernationFull.log | grep -v -e proc -e tmpfs -e WRITE以上命令只显示最后10行,当然如果觉得不够的话可以在f的前面写上想显示的数字行数
不要觉得显示的少,其实因为他筛选出去很多没用的信息,所以显示得不如你输入的行数多,可以输入大一点的数,比如100
tail -100f /var/log/hibernationFull.log | grep -v -e proc -e tmpfs -e WRITE我就随便截取一段(重复的已经删除掉了),抛砖引玉
[626488.811955] syslog-ng(4331): dirtied inode 18 (scemd.log) on md0
[626533.736906] ppid:14083(smbd), pid:28802(smbd), dirtied inode 26993 (smbXsrv_session_global.tdb) on md0
[626533.740237] ppid:14083(smbd), pid:28802(smbd), dirtied inode 22079 (smbpasswd) on md0
[626533.765617] ppid:1(init), pid:6258(syslog-ng), dirtied inode 32395 (.SYNOCONNDB-shm) on md0
[626533.765653] ppid:1(init), pid:6258(syslog-ng), dirtied inode 32067 (.SYNOCONNDB-wal) on md0
[626534.074043] ppid:28800(SYNO.Core.Suppo), pid:28809(synorelayd), dirtied inode 23475 (synorelayd.cfg) on md0
[626534.508386] ppid:1(init), pid:3376(syno_hibernatio), dirtied inode 30981 (hibernationFull.log) on md0比较常见的有这几种:
- syno_hibernatio 调试日志本身
- synologrotated 某日志程序
- synocrond 定时任务(因为是更新啊或者SMART检查之类的)
- logrotate 某日志程序
- synologaccd 某日志程序
- syslog-ng 某日志程序
日志程序咱们没办法,但是发现了一条比较频繁的关于scemd.log的记录
网上搜了下,发现它是辅助群辉休眠后修改硬盘LED灯颜色的一个功能的日志文件
因为黑群辉没有硬盘LED灯,所以自然也就没办法改变,所以不停的往这个日志里面写文件,导致刚休眠就唤醒,解决思路是将该日志放到/tmp目录中
vim /etc.defaults/syslog-ng/patterndb.d/scemd.conf编辑scemd的配置文件
将
destination d_scemd { file("/var/log/scemd.log"); };修改为
destination d_scemd { file("/tmp/scemd.log"); };重启后测试效果

